class: center, middle, inverse, title-slide # OpenML: Connecting R to the Machine Learning Platform OpenML ## whyR? 2018 tutorial - <a href="https://tiny.cc/whyR2018" class="uri">https://tiny.cc/whyR2018</a> ### Giuseppe Casalicchio, Bernd Bischl, Heidi Seibold, Joaquin Vanschoren ### <em>If you haven’t done so yet, create an account on OpenML.org, and install the OpenML R package and either packages farff or RWeka</em> --- <!-- For this to work, install xaringan (devtools::install_github('yihui/xaringan')) --> ## What is OpenML? [openml.org](http://www.openml.org/) <img src="slides_tutorial_files/screenshot.png" width="800px" /> --- ## What is OpenML? <img src="slides_tutorial_files/overview.png" width="800px" /> --- ## Preliminaries - If you haven't done so yet, create an account on [OpenML.org](www.openml.org). - If you haven't done so yet, install the OpenML R package and one of the packages farff or RWeka: ```r install.packages("OpenML") install.packages("farff") # or install.packages("RWeka") ``` ```r library("OpenML") ``` - If something is not clear / you have a question / you have a problem, please **let us know**! - We will have lots of practicals, if you are faster than others, you can check out https://www.openml.org/guide or help others. --- Help  --- ## OpenML whyR? Tutorial Learning goals: - Understand the **potentials** of OpenML - Use the OpenML **online platform** and the **R package** + Creating, uploading and downloading + Running algorithms on OpenML tasks - Know about cool OpenML **projects** and how to **get involved** --- ### Installation and configuration <!-- [3 minutes, Joaquin] --> You need OpenML and an ARFF reader ```r install.packages(c("OpenML","farff")) ``` ```r library("OpenML") ``` --- To **upload** stuff to OpenML, you will need an OpenML API key ```r setOMLConfig(apikey = "c1994bdb7ecb3c6f3c8f3b35f4b47f1f") ``` - Find your own key in your OpenML profile - Without this key, you can still download and retreive information from OpenML  --- Permanently save your API disk to your config file (~/.openml/config) ```r saveOMLConfig(apikey = "c1994...47f1f", overwrite=TRUE) ``` Other configuration options: - `server`: default https://www.openml.org/api/v1 - `cachedir`: cache directory - `verbosity`: 0 (normal) - 2 (debug) - `arff.reader`: 'farff' (default) or 'RWeka' - `confirm.upload`: default FALSE View your configuration ```r getOMLConfig() ``` ``` ## OpenML configuration: ## server : https://www.openml.org/api/v1 ## cachedir : C:\Users\Giuseppe\Repos\openml-r/tests/cache ## verbosity : 1 ## arff.reader : farff ## confirm.upload : FALSE ## apikey : ***************************9aa32 ``` --- ### Listing datasets <!-- [7 minutes, Joaquin] --> ```r datasets = listOMLDataSets() # get first 5K results (LIMIT option) colnames(datasets) ``` ``` ## [1] "data.id" ## [2] "name" ## [3] "version" ## [4] "status" ## [5] "format" ## [6] "tags" ## [7] "majority.class.size" ## [8] "max.nominal.att.distinct.values" ## [9] "minority.class.size" ## [10] "number.of.classes" ## [11] "number.of.features" ## [12] "number.of.instances" ## [13] "number.of.instances.with.missing.values" ## [14] "number.of.missing.values" ## [15] "number.of.numeric.features" ## [16] "number.of.symbolic.features" ``` --- ### Listing datasets ```r datasets[1:5, c(1,2,11,12)] # subset for compact display ``` ``` ## data.id name number.of.features number.of.instances ## 1 2 anneal 39 898 ## 2 3 kr-vs-kp 37 3196 ## 3 4 labor 17 57 ## 4 5 arrhythmia 280 452 ## 5 6 letter 17 20000 ``` --- ### Listing tasks ```r tasks = listOMLTasks() # limits results again colnames(tasks)[1:20] ``` ``` ## [1] "task.id" "task.type" ## [3] "data.id" "name" ## [5] "status" "format" ## [7] "estimation.procedure" "evaluation.measures" ## [9] "target.feature" "cost.matrix" ## [11] "source.data.labeled" "target.feature.event" ## [13] "target.feature.left" "target.feature.right" ## [15] "quality.measure" "majority.class.size" ## [17] "max.nominal.att.distinct.values" "minority.class.size" ## [19] "number.of.classes" "number.of.features" ``` --- ### Listing tasks ```r tasks[1:5, 1:9] ``` ``` ## task.id task.type data.id name status format ## 1 2 Supervised Classification 2 anneal active ARFF ## 2 3 Supervised Classification 3 kr-vs-kp active ARFF ## 3 4 Supervised Classification 4 labor active ARFF ## 4 5 Supervised Classification 5 arrhythmia active ARFF ## 5 6 Supervised Classification 6 letter active ARFF ## estimation.procedure evaluation.measures target.feature ## 1 10-fold Crossvalidation predictive_accuracy class ## 2 10-fold Crossvalidation <NA> class ## 3 10-fold Crossvalidation predictive_accuracy class ## 4 10-fold Crossvalidation predictive_accuracy class ## 5 10-fold Crossvalidation <NA> class ``` --- ### Listing tasks ```r listOMLTasks(data.name = "sonar")[1:4, 1:8] ``` ``` ## task.id task.type data.id name status format ## 1 39 Supervised Classification 40 sonar active ARFF ## 2 98 Learning Curve 40 sonar active ARFF ## 3 269 Supervised Classification 40 sonar active ARFF ## 4 1738 Learning Curve 40 sonar active ARFF ## estimation.procedure evaluation.measures ## 1 10-fold Crossvalidation predictive_accuracy ## 2 10 times 10-fold Learning Curve predictive_accuracy ## 3 33% Holdout set predictive_accuracy ## 4 10-fold Learning Curve predictive_accuracy ``` --- ### Listing flows ```r flows = listOMLFlows() flows[5768:5770, c(1, 3, 4, 6)] ``` ``` ## flow.id name version uploader ## 5768 8432 mlr.regr.glm 1 5541 ## 5769 8433 mlr.classif.naiveBayes 10 5541 ## 5770 8434 mlr.classif.ada 2 5541 ``` --- ### Listing runs and evaluations Runs and evaluations need at least one of: task.id, flow.id, run.id, uploader.id, tag ```r runs = listOMLRuns(task.id = 39) runs[1:3, ] ``` ``` ## run.id task.id setup.id flow.id uploader error.message ## 1 12 39 2 57 1 <NA> ## 2 27 39 14 72 1 <NA> ## 3 60 39 8 63 1 <NA> ``` ```r evals = listOMLRunEvaluations(task.id = 39) evals[1:3, c("flow.name", "predictive.accuracy", "usercpu.time.millis")] ``` ``` ## flow.name predictive.accuracy usercpu.time.millis ## 1 weka.OneR(1) 0.634615 NA ## 2 weka.SMO_RBFKernel(1) 0.692308 NA ## 3 weka.HoeffdingTree(1) 0.677885 NA ``` --- ### Downloading datasets <!-- [10 minutes, Joaquin] --> ```r sonar = getOMLDataSet(data.id = 40) sonar ``` ``` ## ## Data Set 'sonar' :: (Version = 1, OpenML ID = 40) ## Default Target Attribute: Class ``` Extract the `data.frame` from the `OMLDataSet` object: ```r sonar$data[1:5, 1:5] # or as.data.frame(sonar)[1:5, 1:5] ``` ``` ## attribute_1 attribute_2 attribute_3 attribute_4 attribute_5 ## 0 0.0200 0.0371 0.0428 0.0207 0.0954 ## 1 0.0453 0.0523 0.0843 0.0689 0.1183 ## 2 0.0262 0.0582 0.1099 0.1083 0.0974 ## 3 0.0100 0.0171 0.0623 0.0205 0.0205 ## 4 0.0762 0.0666 0.0481 0.0394 0.0590 ``` --- ### Downloading datasets For convenience, you can also download the dataset by its name ```r getOMLDataSet(data.name = "sonar") ``` ``` ## ## Data Set 'sonar' :: (Version = 1, OpenML ID = 40) ## Default Target Attribute: Class ``` --- ### Downloading tasks ```r task = getOMLTask(task.id = 39) task ``` ``` ## ## OpenML Task 39 :: (Data ID = 40) ## Task Type : Supervised Classification ## Data Set : sonar :: (Version = 1, OpenML ID = 40) ## Target Feature(s) : Class ## Tags : basic, mythbusting, mythbusting_1, study_1, study_107, study_123, study_15, s... ## Estimation Procedure : Stratified crossvalidation (1 x 10 folds) ## Evaluation Measure(s): predictive_accuracy ``` Extract the `data.frame` from the `OMLTask` object: ```r task$input$data.set$data[1:3, 1:5] # or as.data.frame(task)[1:3, 1:5] ``` ``` ## attribute_1 attribute_2 attribute_3 attribute_4 attribute_5 ## 0 0.0200 0.0371 0.0428 0.0207 0.0954 ## 1 0.0453 0.0523 0.0843 0.0689 0.1183 ## 2 0.0262 0.0582 0.1099 0.1083 0.0974 ``` --- ### Downloading flows ```r flow = getOMLFlow(flow.id = 100) flow ``` ``` ## ## Flow 'weka.J48' :: (Version = 2, Flow ID = 100) ## External Version : Weka_3.7.5_9117 ## Dependencies : Weka_3.7.5 ## Number of Flow Parameters: 12 ## Number of Flow Components: 0 ``` --- ### Downloading runs ```r run = getOMLRun(run.id = 9203978) run ``` ``` ## ## OpenML Run 9203978 :: (Task ID = 39, Flow ID = 8611) ## User ID : 348 ## Learner : mlr.classif.rpart(52) ## Task type: Supervised Classification ``` --- ### Caching - The package caches most objects on disk (cachedir in config) - Results of listing calls are cached in memory - You can also pre-fill the cache with objects, especially useful on clusters ```r populateOMLCache(data.ids = 1:2, task.ids = 11:12) ``` ``` cache/ ├── datasets │ └── 40 │ ├── dataset.arff │ └── description.xml ├── flows │ └── 100 │ └── flow.xml ├── runs │ └── 9203978 │ ├── predictions.arff │ └── run.xml └── tasks └─── 39 ├── datasplits.arff └── task.xml ``` --- ### Running and uploading <!-- [10 minutes, Bernd] --> Create a run: 1. Define a learner using the `mlr` package 2. Apply to a task using `runTaskMlr()` ```r # create a randomForest learner lrn = makeLearner("classif.randomForest", mtry = 2) # download a task (or get from cache) task = getOMLTask(task.id = 39) # runs the learner locally, uses benchmark internally run.mlr = runTaskMlr(task, lrn) ``` - The `run.mlr` object contains three slots + `run`: contains the information of the run, i.e., the hyperparameter values and the learner predictions. + `bmr`: the `BenchmarkResult` object containing the results of the learner that is applied on the task. + `flow`: contains information about the algorithm. --- ### Running and uploading ```r run.mlr ``` ``` ## $run ## ## OpenML Run NA :: (Task ID = 39, Flow ID = NA) ## ## $bmr ## task.id learner.id acc.test.join timetrain.test.sum ## 1 sonar classif.randomForest 0.8605769 6.86 ## timepredict.test.sum ## 1 0.63 ## ## $flow ## ## Flow 'mlr.classif.randomForest' :: (Version = NA, Flow ID = NA) ## External Version : R_3.4.4-v2.628b87e5 ## Dependencies : R_3.4.4, OpenML_1.8, mlr_2.12.1, randomForest_4.6.14 ## Number of Flow Parameters: 20 ## Number of Flow Components: 0 ## ## attr(,"class") ## [1] "OMLMlrRun" ``` <!-- From a didactical standpoint I would not include this: --> <!-- - Extract the `BenchmarkResult` object via ```r convertOMLMlrRunToBMR(run.mlr) ``` ``` ## task.id learner.id acc.test.join timetrain.test.sum ## 1 sonar classif.randomForest 0.8605769 6.86 ## timepredict.test.sum ## 1 0.63 ``` --> --- ### Running and uploading Upload run to OpenML server: ```r run.id = uploadOMLRun(run.mlr) ``` ```r run.id ``` ``` ## [1] 9203978 ``` - The server assigns a `run.id` which can be used to - download the run: `getOMLRun(run.id)`, or - look up the run online on https://www.openml.org/r/9203978. - Server auto-computes many evaluation measures from predictions <!-- - It is also possible to upload runs with specific tags using the `tags` argument, so that finding the run with a specific tag becomes easier. --> --- ### Running and uploading Let's check that we can get our run back: ```r getOMLRun(run.id) ``` ``` ## ## OpenML Run 9203978 :: (Task ID = 39, Flow ID = 8611) ## User ID : 348 ## Learner : mlr.classif.rpart(52) ## Task type: Supervised Classification ``` --- ### Tags <!-- [10 minutes, Heidi] --> Use tags to sort and find data, tasks, flows and runs easier. Upload entities with tags: ```r uploadOMLDataSet(mydata, tags = c("tag", "tag2")) uploadOMLFlow(myflow, tags = c("tag", "tag2")) uploadOMLRun(myrun, tags = c("tag", "tag2")) ``` Add and remove tags: ```r tagOMLObject(id, object = "run", tags = c("tag", "tag2")) # add tags untagOMLObject(id, object = "run", tags = "tag") # remove tags ``` Add and remove tags online  --- ### Studies You can combine *datasets*, *tasks*, *flows* and *runs* into studies by add the special tag `study_XX` **after** a study has been created. Studies get their own website, e.g. https://www.openml.org/s/30, which can be linked to publications so that others can find all the details online. 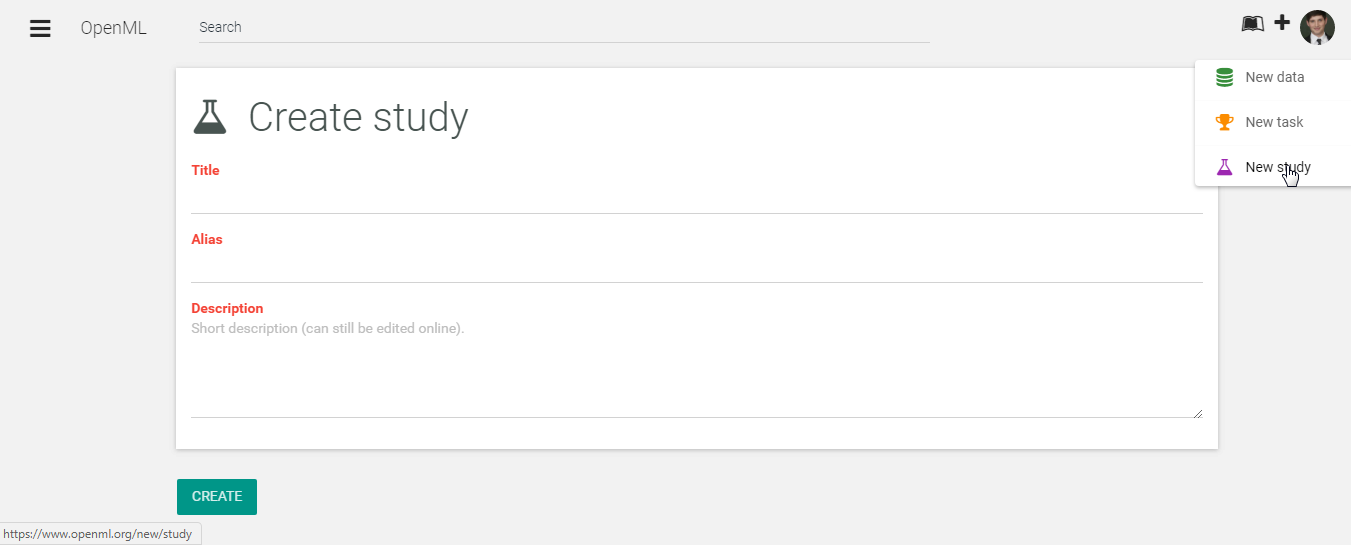 --- ### Studies List all studies on OpenML ```r studies = listOMLStudies() studies[c(13, 26, 67), ] ``` ``` ## study.id alias ## 13 14 OpenML100 ## 26 30 Study_30 ## 67 99 OpenML-CC18 ## name ## 13 Collaborative, reproducible benchmarking and analysis ## 26 OpenML Paper Study ## 67 OpenML Benchmarking Suites and the OpenML-CC18 ## creation.date creator ## 13 2016-04-28 02:39:17 2 ## 26 2016-09-16 17:36:38 348 ## 67 2018-02-23 16:12:26 1 ``` --- ### Studies Get information of a single study ```r getOMLStudy(30) ``` ``` ## ## Study 'OpenML Paper Study' (Study ID 30) ## Description : Compare several trees, bagged trees and the random forest. ## Creation Date : 2016-09-16 17:36:38 ## Tag(s) : study_30 ## Number of Data Sets : 6 ## Number of Tasks : 6 ## Number of Flows : 6 ## Number of Runs : 36 ``` --- ### Evaluations ```r evals = listOMLRunEvaluations(tag = "study_30") evals[1:3, c("data.name", "learner.name", "predictive.accuracy")] ``` ``` ## data.name learner.name predictive.accuracy ## 1 diabetes classif.randomForest 0.772135 ## 2 sonar classif.randomForest 0.817308 ## 3 haberman classif.randomForest 0.748366 ``` 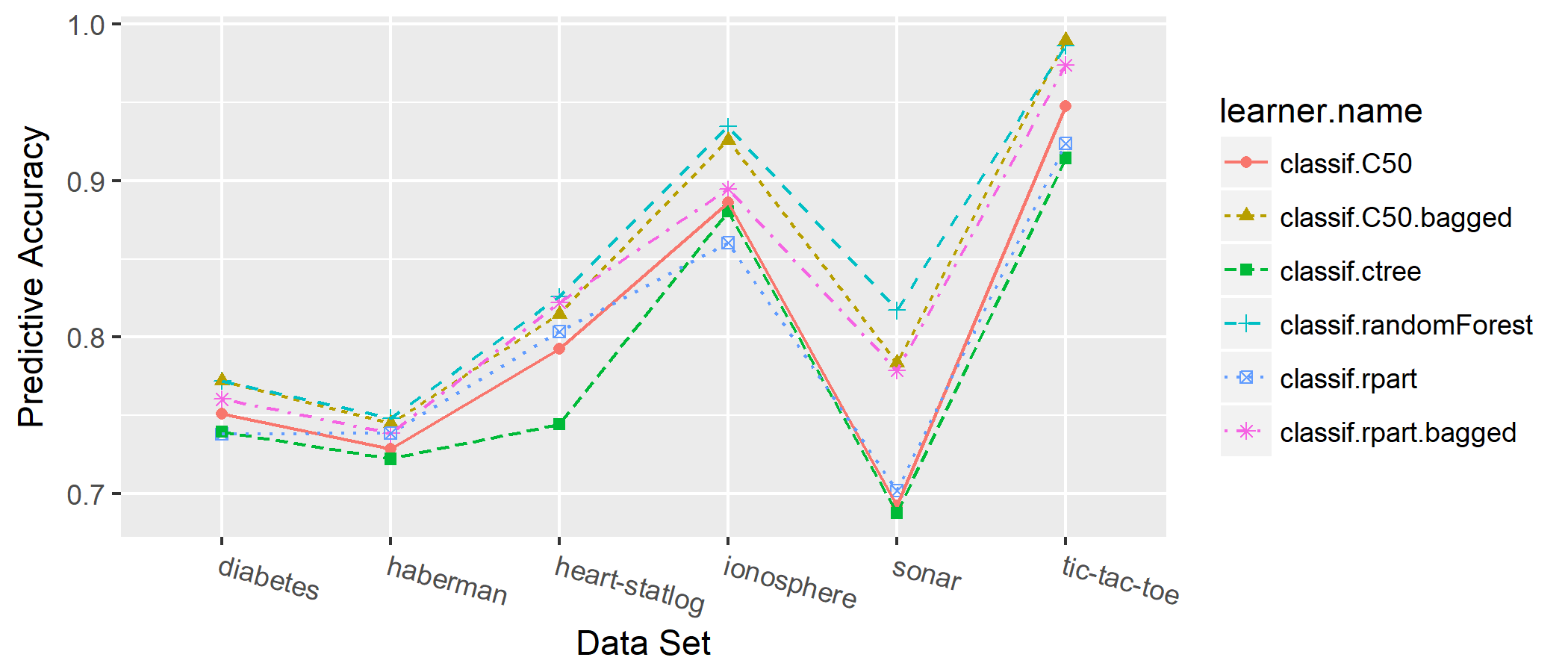<!-- --> --- ### OpenML in science Scientific publications: - [OpenML platform](https://arxiv.org/abs/1407.7722) - [OpenML R package](https://arxiv.org/abs/1701.01293) - [OpenML benchmark suite](https://arxiv.org/abs/1708.03731) Repositories where you can contribute: - **[openml/OpenML](https://github.com/openml/openml)**: The OpenML web application, including the REST API. - **[openml/openml-python](https://github.com/openml/openml-python)**: The Python API, to talk to OpenML from Python scripts (incl. scikit-learn). - **[openml/openml-r](https://github.com/openml/openml-r)**: The R API, to talk to OpenML from R scripts (incl. mlr). - **[openml/java](https://github.com/openml/java)**: The Java API, to talk to OpenML from Java scripts. - **[openml/openml-weka](https://github.com/openml/openml-weka)**: The WEKA plugin, to talk to OpenML from the WEKA toolbox. ## See also the guide on [how to contribute!](https://github.com/openml/OpenML/wiki/How-to-contribute) --- background-image: url(slides_tutorial_files/cool_stuff_text.png) background-size: 70% auto ### Cool stuff people are already doing with OpenML <!-- [15 minutes, Heidi] --> ??? Image-credit: https://commons.wikimedia.org --- ### OpenML Bot - Currently completing 100.000+ runs per day on Azure - Exploring hyperparameters of xgboost, ranger, and other popular machine learning algorithms - Using 75 datasets from study_14  --- ### OpenML meta learning: Making defaults great again! - Choose between different performance measures (AUC, RMSE, ...) - Predict the pareto front for this measure and the training time - E. g. for xgboost: Prediction for hyperparameters on a new dataset, which will outperform the defaults  --- ### OpenML in drug discovery Predict which drugs will inhibit certain proteins (and hence viruses, parasites, ...)  <!-- <img src="slides_tutorial_files/qsar.pdf" width="4200" height="4200"> --> <!-- <object data="slides_tutorial_files/qsar.pdf" type="application/pdf" width="700px" height="700px"> --> <!-- <embed src="slides_tutorial_files/qsar.pdf"> --> <!-- This browser does not support PDFs. Please download the PDF to view it: <a href="slides_tutorial_files/qsar.pdf">Download PDF</a>.</p> --> <!-- </embed> --> <!-- </object> --> --- class: inverse, center, middle  Thanks to all the great folks who have been contributing to OpenML and the R package.