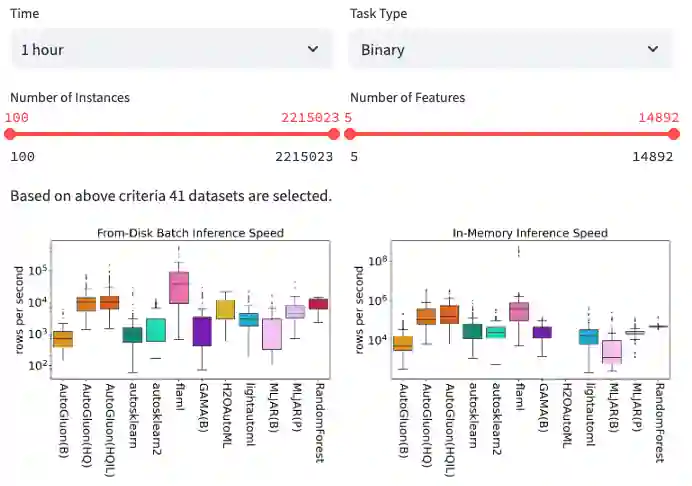
Results
⚠️ Our paper outlines
important limitations for the interpretation of
results. These limitations include:
- We use AutoML framework versions from September 2021, many frameworks have since seen major updates.
- We use the "benchmark" modes of the frameworks, which generally only optimize for performance. Most AutoML frameworks have multiple modes to support different use cases.
- Results can not be used to make conclusions about which algorithm is best, as all frameworks differ in multiple ways.
- Performance statistics are often independent from many qualitative differences, such as ease of use or interpretability.
All our latest results are available on in our MinIO bucket: https://openml1.win.tue.nl/automlbenchmark2023 📂.
We share the tools we used for generating the figures in our paper. The best way to explore the results is through our interactive Streamlit app. It loads the latest results by default. It is also possible to use our notebooks which contain additional visualizations. Data from our 2021 benchmark is available as raw files.