
Note
Go to the end to download the full example code
van Rijn and Hutter (2018)¶
A tutorial on how to reproduce the paper Hyperparameter Importance Across Datasets.
This is a Unix-only tutorial, as the requirements can not be satisfied on a Windows machine (Untested on other systems).
Publication¶
# License: BSD 3-Clause
import sys
if sys.platform == "win32": # noqa
print(
"The pyrfr library (requirement of fanova) can currently not be installed on Windows systems"
)
exit()
import json
import fanova
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import openml
With the advent of automated machine learning, automated hyperparameter optimization methods are by now routinely used in data mining. However, this progress is not yet matched by equal progress on automatic analyses that yield information beyond performance-optimizing hyperparameter settings. In this example, we aim to answer the following two questions: Given an algorithm, what are generally its most important hyperparameters?
This work is carried out on the OpenML-100 benchmark suite, which can be
obtained by openml.study.get_suite('OpenML100'). In this example, we
conduct the experiment on the Support Vector Machine (flow_id=7707)
with specific kernel (we will perform a post-process filter operation for
this). We should set some other experimental parameters (number of results
per task, evaluation measure and the number of trees of the internal
functional Anova) before the fun can begin.
Note that we simplify the example in several ways:
We only consider numerical hyperparameters
We consider all hyperparameters that are numerical (in reality, some hyperparameters might be inactive (e.g.,
degree) or irrelevant (e.g.,random_state)We assume all hyperparameters to be on uniform scale
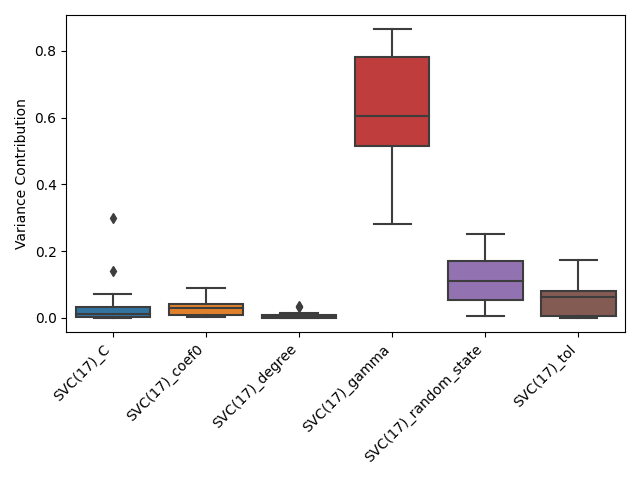
Any difference in conclusion between the actual paper and the presented results is most likely due to one of these simplifications. For example, the hyperparameter C looks rather insignificant, whereas it is quite important when it is put on a log-scale. All these simplifications can be addressed by defining a ConfigSpace. For a more elaborated example that uses this, please see: https://github.com/janvanrijn/openml-pimp/blob/d0a14f3eb480f2a90008889f00041bdccc7b9265/examples/plot/plot_fanova_aggregates.py # noqa F401
suite = openml.study.get_suite("OpenML100")
flow_id = 7707
parameter_filters = {"sklearn.svm.classes.SVC(17)_kernel": "sigmoid"}
evaluation_measure = "predictive_accuracy"
limit_per_task = 500
limit_nr_tasks = 15
n_trees = 16
fanova_results = []
# we will obtain all results from OpenML per task. Practice has shown that this places the bottleneck on the
# communication with OpenML, and for iterated experimenting it is better to cache the results in a local file.
for idx, task_id in enumerate(suite.tasks):
if limit_nr_tasks is not None and idx >= limit_nr_tasks:
continue
print(
"Starting with task %d (%d/%d)"
% (task_id, idx + 1, len(suite.tasks) if limit_nr_tasks is None else limit_nr_tasks)
)
# note that we explicitly only include tasks from the benchmark suite that was specified (as per the for-loop)
evals = openml.evaluations.list_evaluations_setups(
evaluation_measure,
flows=[flow_id],
tasks=[task_id],
size=limit_per_task,
output_format="dataframe",
)
performance_column = "value"
# make a DataFrame consisting of all hyperparameters (which is a dict in setup['parameters']) and the performance
# value (in setup['value']). The following line looks a bit complicated, but combines 2 tasks: a) combine
# hyperparameters and performance data in a single dict, b) cast hyperparameter values to the appropriate format
# Note that the ``json.loads(...)`` requires the content to be in JSON format, which is only the case for
# scikit-learn setups (and even there some legacy setups might violate this requirement). It will work for the
# setups that belong to the flows embedded in this example though.
try:
setups_evals = pd.DataFrame(
[
dict(
**{name: json.loads(value) for name, value in setup["parameters"].items()},
**{performance_column: setup[performance_column]}
)
for _, setup in evals.iterrows()
]
)
except json.decoder.JSONDecodeError as e:
print("Task %d error: %s" % (task_id, e))
continue
# apply our filters, to have only the setups that comply to the hyperparameters we want
for filter_key, filter_value in parameter_filters.items():
setups_evals = setups_evals[setups_evals[filter_key] == filter_value]
# in this simplified example, we only display numerical and float hyperparameters. For categorical hyperparameters,
# the fanova library needs to be informed by using a configspace object.
setups_evals = setups_evals.select_dtypes(include=["int64", "float64"])
# drop rows with unique values. These are by definition not an interesting hyperparameter, e.g., ``axis``,
# ``verbose``.
setups_evals = setups_evals[
[
c
for c in list(setups_evals)
if len(setups_evals[c].unique()) > 1 or c == performance_column
]
]
# We are done with processing ``setups_evals``. Note that we still might have some irrelevant hyperparameters, e.g.,
# ``random_state``. We have dropped some relevant hyperparameters, i.e., several categoricals. Let's check it out:
# determine x values to pass to fanova library
parameter_names = [
pname for pname in setups_evals.columns.to_numpy() if pname != performance_column
]
evaluator = fanova.fanova.fANOVA(
X=setups_evals[parameter_names].to_numpy(),
Y=setups_evals[performance_column].to_numpy(),
n_trees=n_trees,
)
for idx, pname in enumerate(parameter_names):
try:
fanova_results.append(
{
"hyperparameter": pname.split(".")[-1],
"fanova": evaluator.quantify_importance([idx])[(idx,)]["individual importance"],
}
)
except RuntimeError as e:
# functional ANOVA sometimes crashes with a RuntimeError, e.g., on tasks where the performance is constant
# for all configurations (there is no variance). We will skip these tasks (like the authors did in the
# paper).
print("Task %d error: %s" % (task_id, e))
continue
# transform ``fanova_results`` from a list of dicts into a DataFrame
fanova_results = pd.DataFrame(fanova_results)
Starting with task 3 (1/15)
Starting with task 6 (2/15)
Starting with task 11 (3/15)
Starting with task 12 (4/15)
Starting with task 14 (5/15)
Starting with task 15 (6/15)
Starting with task 16 (7/15)
Starting with task 18 (8/15)
Starting with task 20 (9/15)
Starting with task 21 (10/15)
Starting with task 22 (11/15)
Starting with task 23 (12/15)
Starting with task 24 (13/15)
Starting with task 28 (14/15)
Starting with task 29 (15/15)
make the boxplot of the variance contribution. Obviously, we can also use
this data to make the Nemenyi plot, but this relies on the rather complex
Orange dependency (pip install Orange3). For the complete example,
the reader is referred to the more elaborate script (referred to earlier)
fig, ax = plt.subplots()
sns.boxplot(x="hyperparameter", y="fanova", data=fanova_results, ax=ax)
ax.set_xticklabels(ax.get_xticklabels(), rotation=45, ha="right")
ax.set_ylabel("Variance Contribution")
ax.set_xlabel(None)
plt.tight_layout()
plt.show()
Total running time of the script: ( 1 minutes 10.249 seconds)